One-hot encoding is common used in deep learning, n-grams model should be encoded to vector to train. In this tutorial, we will introduce how to encode n-grams to one-hot encoding.
What is one-hot encoding?
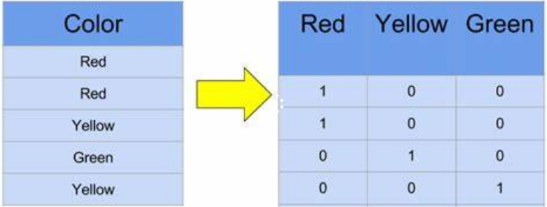
As to a vocabulary, i like writing.
The size of vocabulary is 3.
Eoncode this sentence will be:
i: [1, 0, 0]
like: [0, 1, 0]
writing: [0, 0, 1]
Encode n-grams to one-hot encoding
As to sentence “i like writing“, the trigrams (3-grams) of it is:
[‘#i#’, ‘lik’, ‘ike’, ‘wri’, ‘rit’, ‘iti’, ‘tin’, ‘ing’]
To create word level n-grams, you can read this tutorial.
A Simple Guide to Flatten Python List for Beginners – NLTK Tutorial
Here we will encode n-grams to one-hot encoding with numpy.
Import library
import numpy as np
Prepare n-gram
'''i like writing''' grams = ['#i#', 'lik', 'ike', 'wri', 'rit', 'iti', 'tin', 'ing']
Create a function to encode n-grams
def get_one_hot(targets, nb_classes):
res = np.eye(nb_classes)[np.array(targets).reshape(-1)]
return res.reshape(list(targets.shape)+[nb_classes])
Get n-grams one-hot encoding
words_count = len(grams) one_hots = get_one_hot(np.arange(words_count), words_count) print(one_hots)
The one-hot encoding result is:
[[1. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 0. 0. 0. 0. 1.]]