Position is an important feature for deep learning model. For example, in aspect level sentiment analyis, we can use word position to improve the efficiency of classification (A Position-aware Bidirectional Attention Network for Aspect-level Sentiment Analysis). In this tutorial, we will introduce how to use position in deep learning model.
What is position feature?
Position feature means the position where a word or an image is located in. For example, as to sentence:
| Words | This | is | a | good | place | to | eat |
| Position | 3 | 2 | 1 | 0 | 1 | 2 | 3 |
As to sentiment word: good, we set the position of it to be 0, others will be: 3, 2, 1
The position feature of this sentence is: 3, 2, 1, 0, 1, 2, 3
Position Encoding
We can find position feature is an integer or float number. In order to use it in deep learning model, we often need to convert it to a vector, which means we should encode position feature.
There are two ways to encode position feature:
(1) Learning position embeddings
For example, the count of position is 50, we can create a position embedding to learn.
self.pos_embedding = tf.Variable(tf.random_uniform([50, 200], -0.01, 0.01), dtype=tf.float32)
(2) Computing position embeddings
In Transformer
In June 2017, Vaswani et al. published the paper “Attention Is All You Need”, a postion encoding is proposed.
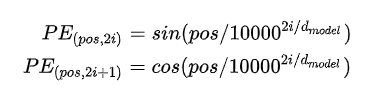
where \(d_model\) is the dimension of position embedding, \(i\) is the i-th index of \d_model\), \(pos\) is the number of position feature. It looks like:

In MemN2N
In MemN2N, a postion encoding is also proposed. It is:

Here \(J\) is total number of position, \(d\) is the dimension of position embedding and \(j\) is the j-th position, \(k\) is the k-th index of \(d\). It looks like:
