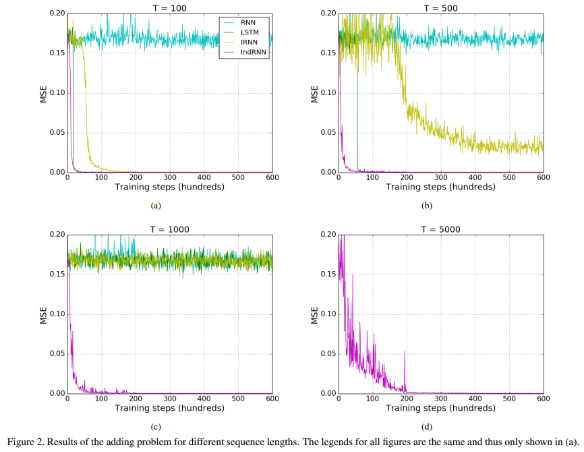
IndRNN is proposed in paper: Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. It can handle longer sequence than LSTM.
How Long Sequence Can be Processed Effectively by LSTM? – LSTM Tutorial
In this tutorial, we will use some examples to introduce this model.
There is a tensorflow project on IndRNN in github. It is:
https://github.com/batzner/indrnn
You can view this project to understand this model.
The core of IndRNN
IndRNN modifies the computation of hidden state in RNN.
\(h_t=\sigma(Wx_t+u\odot h_{t-1}+b)\)
Here\(\odot\) is the hadamard product.\(\sigma\) is the activation function, for example relu().
How about variables in IndRNN
In order to know how many variables in IndRNN, we will use an example to discuss.
Look at example below:
import tensorflow as tf
import numpy as np
from ind_rnn_cell import IndRNNCell
TIME_STEPS = 784
LAST_LAYER_LOWER_BOUND = pow(0.5, 1 / TIME_STEPS)
RECURRENT_MAX = pow(2, 1 / TIME_STEPS)
#5*4*10
batch = 64
inputs = tf.Variable(tf.truncated_normal([64, 40, 200], stddev=0.1), name="S")
input_init = tf.random_uniform_initializer(-0.001, 0.001)
recurrent_init = tf.random_uniform_initializer(LAST_LAYER_LOWER_BOUND,
RECURRENT_MAX)
cell = IndRNNCell(100,
recurrent_max_abs=RECURRENT_MAX,
input_kernel_initializer=input_init,
recurrent_kernel_initializer=recurrent_init)
# Unroll the layer
layer_output, _ = tf.nn.dynamic_rnn(cell, inputs,
dtype=tf.float32,
scope="rnn")
init = tf.global_variables_initializer()
init_local = tf.local_variables_initializer()
with tf.Session() as sess:
sess.run([init, init_local])
np.set_printoptions(precision=4, suppress=True)
a =sess.run(layer_output)
print(a.shape)
for n in tf.trainable_variables():
print(n)In this example, the layer input is inputs, which is batch_size * sequence_length*dim, for example: 64*40*200.
Run this code, you will find:
the layer_output is: (64, 40, 100), it is the same to LSTM output.
The trainable variables in IndRNN are:
<tf.Variable 'rnn/ind_rnn_cell/input_kernel:0' shape=(200, 100) dtype=float32_ref> <tf.Variable 'rnn/ind_rnn_cell/recurrent_kernel:0' shape=(100,) dtype=float32_ref> <tf.Variable 'rnn/ind_rnn_cell/bias:0' shape=(100,) dtype=float32_ref>
We can find: there are only three variables in a IndRNN model. In this example, IndRNN will handle 40 length sequence, however, there are not 40*3 variables in it.
How about recurrent_max_abs?
recurrent_max_abs limits the maximum value in hidden weight \(u\).
For example:
# Clip the absolute values of the recurrent weights to the specified maximum
if self._recurrent_max_abs:
self._recurrent_kernel = clip_ops.clip_by_value(self._recurrent_kernel,
-self._recurrent_max_abs,
self._recurrent_max_abs)
We should notice: the longer sequence , the smaller \(u\).
Because:
LAST_LAYER_LOWER_BOUND = pow(0.5, 1 / TIME_STEPS)
Here TIME_STEPS is the sequence length.
How about kernel initialization of IndRNN in multiple layers?
Here is an example:
RECURRENT_MAX = pow(2, 1 / TIME_STEPS)
for layer in range(1, NUM_LAYERS + 1):
# Init only the last layer's recurrent weights around 1
recurrent_init_lower = 0 if layer < NUM_LAYERS else LAST_LAYER_LOWER_BOUND
recurrent_init = tf.random_uniform_initializer(recurrent_init_lower,
RECURRENT_MAX)
We can find the kernel initialization of last IndRNN is [LAST_LAYER_LOWER_BOUND, RECURRENT_MAX]
How about learning rate?
The default is:
LEARNING_RATE_INIT = 0.0002
Compare LSTM with IndRNN
Here is an comparative result.