When we are building a speaker verification model, we have to build a test set to evaluate the performance of our model. For example, you will use this test to compute EER or minDCF.
How to Compute EER Metrics in Voiceprint and Face Recognition – Machine Leaning Tutorial
How to build test set for speaker verification?
Here some tips we should notice.
Notice 1: use speakers who are not in train set.
It means we can not use the samples of speakers in train set to build a test set. We should use persons who are not in train set to build.
Notice 2: the percent of positive label and negative label should be 1:1
Here
positive label: label = 1, it means two audio files are from the same speaker.
negative label: label = 0, it means two audio files are form two different speakers.
We use voxceleb dataset to be an example:

You can find this file here:
https://www.robots.ox.ac.uk/~vgg/data/voxceleb/meta/list_test_all2.txt
From this example we can find:
(1) positive label : negative label = (label = 1) : (label = 0) = 1:1
(2) each person contain two positive samples and two negative smaples.
Notice 3: the test samples of each speaker should the same
As to example above, every speaker contains four test samples, 2 positive and 2 negative.
Of course, we also can change the test number of each person, for example, each speaker use 5, 6 or 10 test samples.
Notice 4: Use more negative samples to test if you plan to use your model with your company online data
From notice 2, we can find when positive : negative = 1:1, we may get a good EER or minDCF. However, we usually have more negative samples in real life, which means we should more negative samples to test our model.
As to dataset cn-celeb_v2 for an example:
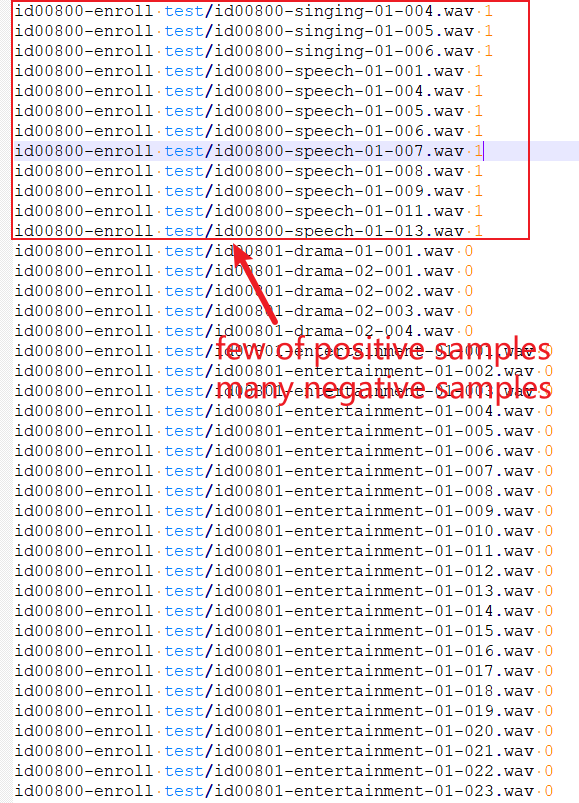
We can find: as to the same person, there are more negative samples than positive samples.
We can use python itertools.combinations() to build this test set.