Channel attention is the core of Squeeze-and-Excitation (SE) block. In this tutorial, we will analysis how to implement it for beginners.
Squeeze-and-Excitation (SE) Block
It is proposed in paper: Squeeze-and-Excitation Networks
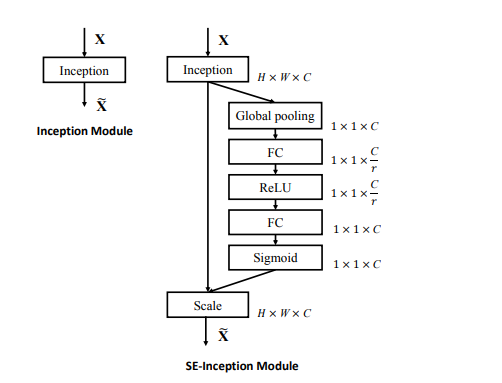
The structure of it as follows:

The implementation of it is below:
We can use it with residual network as follows:

Channel Attention in Squeeze-and-Excitation (SE) Block
The channel attention is computed by sigmoid function in se block. The shape of it is 1*1*C.
Here we will introduce how to calculate channel attention in 1D and 2D matrix by using pytorch.
Implement Squeeze-and-Excitation (SE) Block for 1D Matrix in PyTorch – PyTorch Tutorial
Implement Squeeze-and-Excitation (SE) Block for 2D Matrix in PyTorch – PyTorch Tutorial