When we are processing pdf files with python, we should check a pdf is completed or corrupted. In this tutorial, we will introduce you a simple way to how to detect. You can use this tutorial example in your application.
Some features of completed pdf files
PPF file 1.

The pdf file ends with NUL. Meanwhile, there are many NUL in last line.
The last second line contains: %%EOF

At the middle of this pdf file, there are also a %%EOF.
PDF file 2.

This pdf file ends with NUL, there are only a NUL in the last line.
The last second line also contains a %%EOF.
PDF file 3.

The pdf file ends with unknown symbol. However, the last second line contains a %%EOF.
PDF file 4.

This pdf file ends with %%EOF.
Then check the start of pdf
PDF file 5.
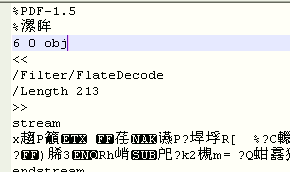
This pdf start with: %PDF
So as to a completed pdf, the feature of it is:
1.The pdf file ends with %%EOF or NUL.
2.This file contain more than one %%EOF symbol.
3. The content of pdf file contains %PDF.
We can create a python function to detect a pdf file is completed or not.
def isFullPdf(f):
end_content = ''
start_content = ''
size = os.path.getsize(f)
if size < 1024: return False
with open(f, 'rb') as fin:
#start content
fin.seek(0, 0)
start_content = fin.read(1024)
start_content = start_content.decode("ascii", 'ignore' )
fin.seek(-1024, 2)
end_content = fin.read()
end_content = end_content.decode("ascii", 'ignore' )
start_flag = False
#%PDF
if start_content.count('%PDF') > 0:
start_flag = True
if end_content.count('%%EOF') and start_flag > 0:
return True
eof = bytes([0])
eof = eof.decode("ascii")
if end_content.endswith(eof) and start_flag:
return True
return FalseI have test this function on more than 1,000 pdf files, it works well.