In order to increase the depth of a neural networks, we can use resnet networks. There are two kinds of resnet structure, Resnet V1 and Resnet V2. How about their structure and which one we should use? In this tutorial, we will discuss this topic.
Look at 5 types of resnet block structures below.

If conv(weight)+BN+ReLU is the basic operation, we can find:
original = resnet v1
full pre-activation = resnet v2
How about their performance?
From paper: Identity Mappings in Deep Residual Networks, we can find:
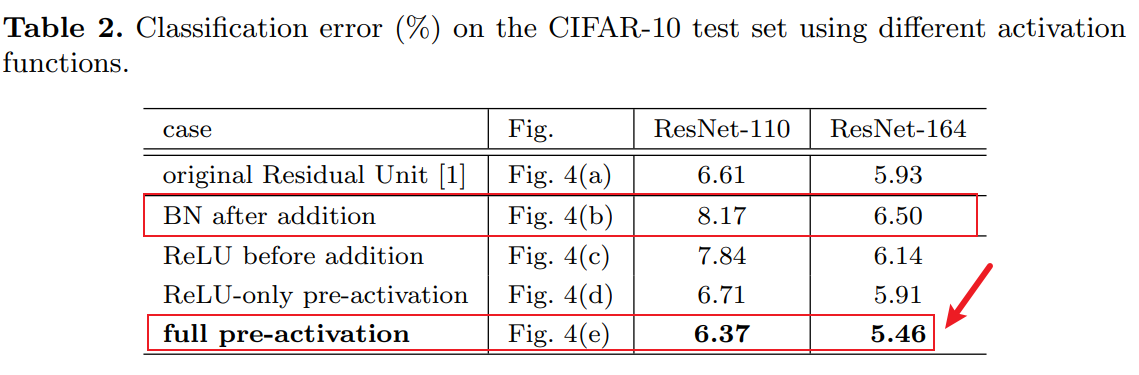
- full pre-activation (resnet v2) has the best performance.
- (b) and (c) has the bad performance.
Because
- the last BN in (b) has change the distribution of \(x_l\)
- the ReLU in (c) make all value is positive.
We also can find:
In order to use resent correctly, we should:
(1) Do not change the value of \(x_l\) lightl, unless you think it is necessary.
(2) Do not use BN (batch norm) after addition operation.