4. How to compute output O?
In memory network, output o is computed as:

where ci is the vector of each word in sentence X.
5.How to compute ci?
Like get mi, we can compute ci with a matrix C(V*d)

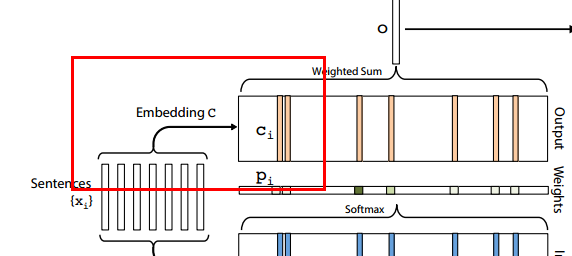
Notice:
(1) matrix C is like matrix A, it is a variable and trained in model. It represents vector of each word in vocabrary.
self.C = tf.Variable(tf.random_normal([self.nwords, self.edim], stddev=self.init_std)) # Embedding C for sentences
(2) If you use pretrained word vector, we can map ci like
ci = Cxi
6.How to compute model output and make classification?
It is computed as:
![]()
(1) why use o+u?
Because when test this network, we inputs X and Q
o contains feature belong to X based on Q
u contains feature belong to Q
so use o+u can enhance the result, however, we also can only use o, which contains information X and Q.
7.Relathon between matrix A and C?
In network, matrix A represents vector of each word with attention weight on Q
C is only vector of each word, do not contain other information and featrue.
In paper: https://arxiv.org/abs/1503.08895
A ≠ C
The key problem is pi, in this paper, matrix A contains word vector and word attention weight information based on Q.
but if pi is computed as
pi=softmax(uTMmi)
M is the attention matrix
Here we can set A=C in this model.
8.How to use multiple layers?
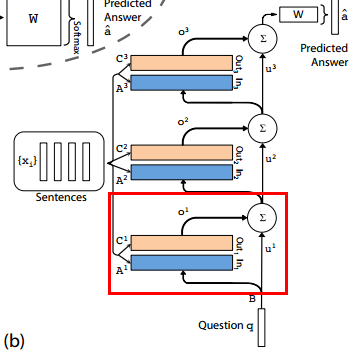
You must use new matrix A,B,C. Compute u as:
