Multi-Head Attention is very popular in nlp. However, there also exists some problems in it. In this tutorial, we will discuss how to implement it in tensorflow.
Multi-Head Attention
If we plan to use 8 heads, Multi-Head Attention can be defined as:
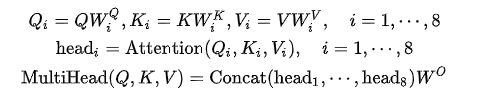
Here each head attention is computed as:
\(Attention(Q_i,K_i,V_i) = softmax(\frac{Q_iK_i^T}{\sqrt{d}})V_i\)
where \(d\) is the dimension of \(Q\), \(K\) and \(V\).
For example, if we use 8 heads, the dimension of \(Q\), \(K\) and \(V\) is 512, each head will be 64 dimension.
In order to implement multi-head attention in tensorflow, we should notice:
- \(Q\), \(K\) and \(V\) are input tensors, they can be the same or not.
- As to weight \(W_i^Q\), \(W_i^K\) and \(W_i^V\), they are different in each head. For example, if you plan to use 8 heads, there will be 3 * 8 = 24 weights.
The structure of Multi-Head Attention is:
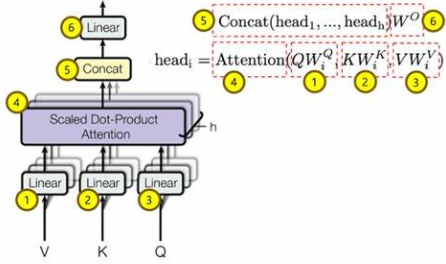
Here is an example to implement multi-head attention in tensorflow.
#[batch_size,input_length,hidden_size*2], for example:64 * 50 * 200
outputs = tf.concat([forward_output, backward_output], axis=2)
# add multihead self-attention
result_list = []
factor = tf.sqrt(tf.constant(self.hidden_size,dtype = tf.float32)) # d in multi-head attention
for k in range(self.head_num):
tmp_str = 'head_' + str(k+1)
with tf.variable_scope(tmp_str): # create weight for each head
w_p = tf.Variable(tf.truncated_normal([self.hidden_size*2, self.hidden_size], stddev=0.1),name = 'w_p')
b_p = tf.Variable(tf.zeros(self.hidden_size),name = 'b_p')
# During training, we should calculate the attention for each sample in the batch
ind = tf.constant(0)
output_ta = tf.TensorArray(dtype=tf.float32, size=self.vary_batch_size)
def cond(ind,output_ta):
return ind < self.vary_batch_size
def body(ind,output_ta):
#[input_length,hidden_size*2]
single = outputs[ind,:,:]
#[input_length,hidden_size]
single = tf.matmul(single,w_p) + b_p
#[input_length,input_length]
#soft_out = tf.nn.softmax( tf.matmul(a = single,b = single,transpose_b=True) / factor, axis = 1 )
soft_out = tf.nn.softmax( tf.matmul(a = single,b = single,transpose_b=True) / factor, dim = 1 ) # dim for tf 1.3.0
#[input_length,hidden_size]
att_out = tf.matmul(soft_out,single)
output_ta = output_ta.write(ind,att_out)
# increment
ind = ind + 1
return ind,output_ta
_,final_output_ta = tf.while_loop(cond,body,[ind,output_ta])
#[batch_size,input_length,hidden_size]
single_output = final_output_ta.stack()
print(type(single_output))
print(single_output.get_shape())
result_list.append(single_output)
#[batch_size,input_length,hidden_size * head_num]
new_outputs = tf.concat(result_list,axis = 2)