Cyclical learning rate policy (CLR) is proposed in paper: Cyclical Learning Rates for Training Neural Networks. In this tutorial, we will use some examples to show you how to use it.
torch.optim.lr_scheduler.CyclicLR()
It is defined as:
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=- 1, verbose=False)
It will set the learning rate of each parameter group according to cyclical learning rate policy (CLR).
We should notice: Cyclical learning rate policy changes the learning rate after every batch. step should be called after a batch has been used for training.
We can view image below to understand this optimizer.

Here are some important parameters we should concern.
base_lr: Initial learning rate which is the lower boundary in the cycle for each parameter group
max_lr: Upper learning rate boundaries in the cycle for each parameter group.
step_size_up: Number of training iterations in the increasing half of a cycle
mode: One of {triangular, triangular2, exp_range}
However, how to set values for these parameters.
As to max_lr, we can set it to the optimizer learning rate, for example: 1e-3
As to base_lr, it can be 1/3 or 1/4 of max_lr, we can see how to set it in paper.
As to step_size_up, we should notice the iterations in each epoch. It can be 2 − 10 times the number of iterations in an epoch.
Here we will use an example to show how it change the learning rate of Adam.
import torch
from matplotlib import pyplot as plt
lr_list = []
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
LR = 0.001
optimizer = torch.optim.Adam(model, lr=LR)
max_lr = 1e-3
min_lr = max_lr / 4
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=min_lr, max_lr=max_lr, cycle_momentum = False, mode='triangular2', step_size_up=17000*6)
for epoch in range(1,80):
data_size = 17000
for i in range(data_size):
optimizer.zero_grad()
#loss
optimizer.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
scheduler.step()
plt.plot(range(len(lr_list)),lr_list,color = 'r')
plt.show()Run this code, we will see the learning rate as follows:
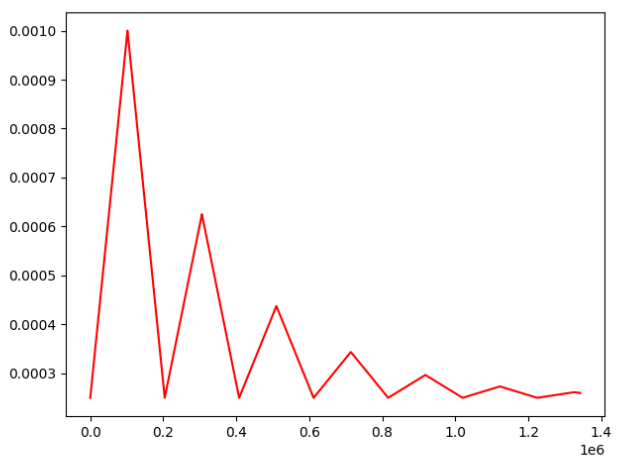
We should notice: we should use scheduler.step() in the batch iteration, which is different from torch.optim.lr_scheduler.StepLR().
Understand torch.optim.lr_scheduler.StepLR() with Examples – PyTorch Tutorial
